当社創業社長であります鈴木清幸は京都大学で人工知能の研究をしておりました。「人とコンピューターとの自然なコミュニケーションを実現する」という想いを持って米国へ調査に赴いた際、カーネギーメロン大学で音声認識システムを開発するグループと懇意になり、その日本語版を共同で開発しないかと声がかかりました。1997年、まだ日本国内では大手メーカーが研究所レベルで取り組んでいた、そんな時代に音声認識システムの開発ベンチャーとして、当社は誕生したのです。
日本では音声認識分野の草分けとしてスタートしたのですが、先駆者だからこそ開発には苦労が伴いました。会社設立の翌年には「全日本難聴者・中途失聴者団体連合会」から、音声から字幕を自動作成できるシステム開発の依頼があったのですが、開発したシステムを連合会と共同で運営する研究会において評価をした際、複雑な日本語の変換精度が基準に達しませんでした。その後、このプロジェクトは中断されましたが、日本語を認識する技術難易度は相当高いものであること、そしてその課題をクリアするために、新しい発想が必要なことが明確になりました。このような様々な試行錯誤が、今のAmiVoiceのコア(図1参照)となる技術「音響モデル」「言語モデル」「発音辞書」という音声認識のための3つの「辞書」をシステムに持たすことによる、精度の高い音声認識システムの開発へとつながっていったのです。
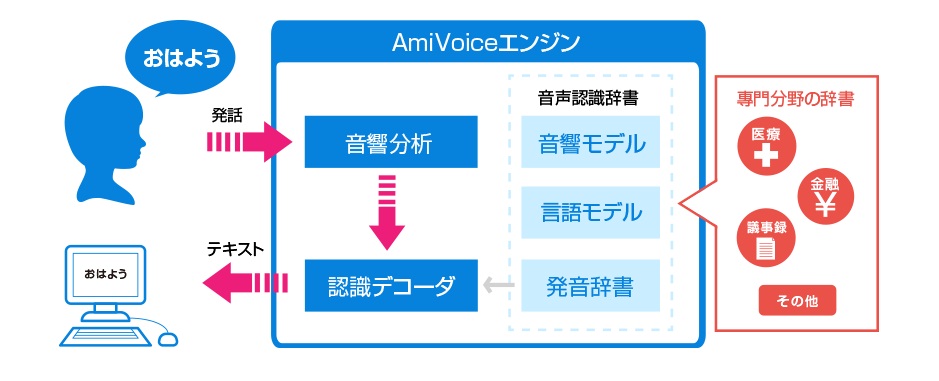
図1:AmiVoiceの音声認識技術の仕組み

池袋サンシャインシティ文化会館にある本社