先ほどお話ししましたようにAmiVoiceの音声認識技術は、「音響モデル」「言語モデル」「発音辞書」の3つを組み合わせたことで実現しましたが、その最大の特徴はテキスト化の正確性です。
そもそも、人が話す言葉はその人によって発音が微妙に違ったりするわけですし、性別や言葉使いなどでも全然違ってきますから、ひと通りだけの認識スタイルでは到底対応できません。そこで発語された言葉をその音の成分から数値的に判断しようというのが「音響モデル」の考え方です。誰が話したとしても正確に認識させるためには、大量の音声サンプルを収集し、周波数成分の分析を行い、音響モデルの元となる音素モデルの作成が必要なため、大変手間のかかる作業です(図2参照)。
また、誤変換を防ぐために、日本語の配列から正確な言葉をチョイスする仕組みも重要でした。こちらも大量の日本語サンプルを統計的に処理し、文脈から適正な言葉を選別できる言語モデルを作りました(図3参照)。
そして、この音響モデルと言語モデルを発音辞書(図4)でつなぐことによって、どんな人が話していても、その音声を認識し、正しいテキストを導き出すことができるのです。

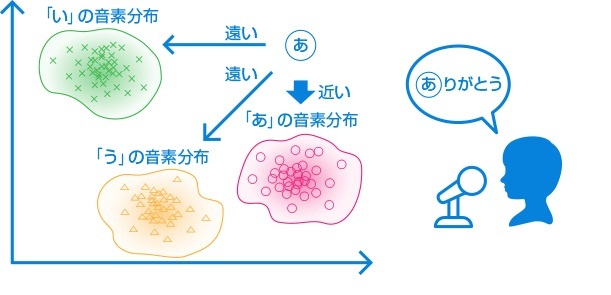
図2:【音響モデル】音声の周波数を切り出し(上左図)、発語された音の特徴を数値化した音素モデル(上右図)を作成。
大量の音素モデルの集合体である音響モデル(下図)を作成する

図3:【言語モデル】文字列や単語列が適切かを判断するために統計処理をしたもの
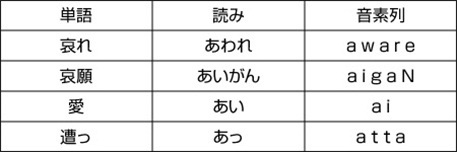
図4:【発音辞書】単語を一語づつに分解し、音素モデルを組み合わせた単語音響モデルを構成する